
I am working as a Data scientist at Witty Works with a focus on NLP development. In a recent blog post, Barbara introduced you to our new product called Witty, a tool that helps you write consciously. The idea is to use language in a way that makes people feel welcome whenever you write any text, such as newsletters, job advertisements, or marketing campaigns. In this blog post, I will first describe what NLP is, how we use it, and what lies behind the magic: how we can assist users in writing more diversely and inclusively with the help of NLP.
What does NLP mean?
NLP stands for Natural language processing, not to be confused with Neuro-linguistic programming, which also uses NLP as an abbreviation. Natural language processing is a technology at the intersection of linguistics, computer science, and artificial intelligence (AI). AI is an umbrella term for technologies that enable machines to simulate human intelligence. AI includes systems that mimic cognitive abilities, such as language understanding and generation, machine vision, and decision making. AI covers a wide range of applications, from self-driving cars to predictive systems.
Computers are generally not designed to understand human communication. For us, making sense of a text is simple: we recognize individual words and the context in which they're used. But computers speak in code. Natural Language Processing aims to make human language ‒ which is complex, ambiguous, and highly diverse ‒ easy for machines to understand. NLP can process various types of speech, including slang, dialects, and misspellings. With NLP, computers can understand written or spoken text and perform tasks such as translating, extracting keywords, categorizing topics, and more. Very well-known places where it's used, for example, are search engines (like Google), grammar spell check applications (Grammarly), or chatbots.
Text analysis and Machine Learning
Handling text intelligently is tricky: sometimes words that look different mean the same thing, and sometimes the exact words in another order or context mean something completely different. In most cases, linguistic knowledge is required to extract useful information from the text. Linguistic text analysis can be broken into several sub-categories, including morphological, grammatical, syntactic, and semantic analyses. However, to automate these processes and get accurate answers, you need machine learning. Machine learning is the process of applying algorithms that teach machines to automatically learn and improve from previously collected data without explicit programming. All major machine learning technologies are trained from human-labeled datasets. It builds a particular type of database, and then, using grammatical and human-created rules, machines produce patterns to find the needed results. The rules provide computers with step-by-step instructions for how to complete a specific task. For example, a human labels the words in a text as nouns, verbs, and pronouns. The machine then learns from these examples until it can label new sentences correctly by itself. With NLP, computers can also find the word dependencies to analyze its grammatical structure in the sentence and extract different types of crucial elements such as people names, dates, locations, and companies.
Witty
We develop a tool, Witty, to assist you in writing more inclusively. Witty's NLP core is based on the following steps:
- In the first step, we created dictionaries of non-inclusive words for different categories, e.g., boasting words, gendered words, ableist language, racist language, etc., and their alternatives in German and English. This work is done with the help of Tracey, our highly trained language specialist. The quality of data in the dictionaries is essential. All non-inclusive words were carefully collected from different resources, including scientific research, inclusive language guides by various associations, and guides to conscious language. All these data are continuously managed and checked.
- In the second step, we simulate understanding the text by applying NLP. We use NLP pre-trained models for German and English correspondingly to transform the words in the text into dictionary-like forms (which are called "lemmas"), perform linguistic analysis, and extract the linguistic features from the text. For example, the sentence "Er liest Bücher" will be transformed into "Ich lesen Buch" with morphological labels (plural and singular forms, gender), part-of-speech tags (pronouns, verbs, nouns, adjectives, etc), word dependencies labels. In this step, we also do named entity recognitions to extract geographic location, organization's name, people, numbers from the user text if needed. After that, we search through our inclusive and non-inclusive dictionaries if any of the words or idioms from the user's text belong to them or not.
- In the third step, we highlight the words related to non-inclusive language, propose the alternatives, give the reason for using communal language, and explain why this word is non-inclusive. We also highlight inclusive words to show and encourage people to use them more often.
See NLP in practice
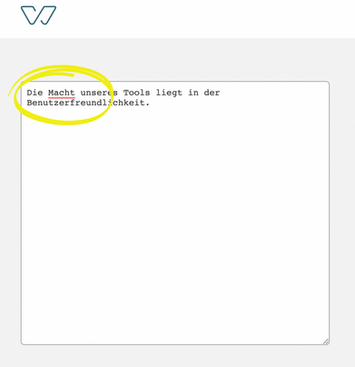
Let's dive into concrete examples to understand the magic behind the scene. The German word "Macht" is agentic, describing attributes that enforce the male stereotype and should be caught and highlighted by the algorithm. However, there exists "macht" as the form of the verb "machen", which is a common word and should not be highlighted by the algorithm.
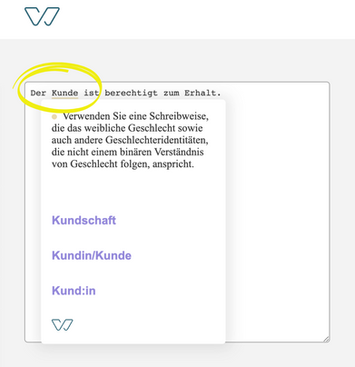
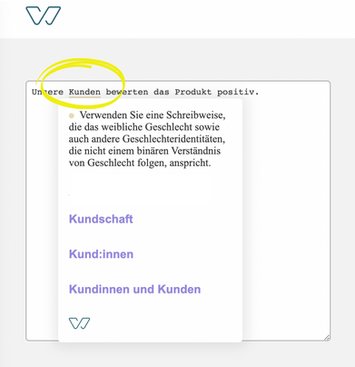
NLP also helps to perform morphological analysis of the text and, for example, to show the correct form of alternatives for plural and singular cases.
The following specific case shows that we highlight
words depending on their context. For example, the
word international is a term that has become a
hollow word because it has been overused in the
business environment. But in the case "Greenpeace
ist eine internationale Organisation", the use of
this word is correct. NLP recognizes that Greenpeace
is an organization and that international belongs to
this word and should therefore not highlight it.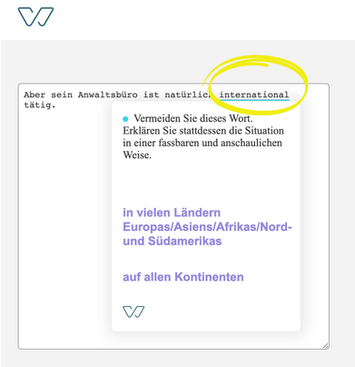
What makes Witty a helpful product as
well is the
check of spelling and grammar mistakes.
"Witty" is a fresh product. We are currently collecting the data to move forward to more advanced NLP models based on neural networks that will help us move to text generation and style transfer. In this case, we will not just substitute the words and idioms but rephrase the text and propose the inclusive style for the whole text.
In conclusion
Behind the scenes, NLP analyzes the grammatical structure of sentences and the specific meaning of words, then uses algorithms to extract meaning and output the results. You can see that Artificial intelligence is far away from human intelligence. In other words, it makes sense of human language in order to automatically perform various tasks. Usually, people can accomplish a new language task using just a few examples or simple instructions - something that modern NLP algorithms still struggle to do. We hope this blog post took some of the fear of AI away from you and showed you how we use AI in the Witty tool. Let us know if you have more questions about how our algorithms work.
Are you interested in finding out more?
If you are looking for a digital writing assistant for inclusive language, try out Witty for free. Witty detects non-inclusive language and provides ongoing training on unconscious bias and operationalizes inclusion.



